The goal of Carbon Cycle Data Assimilation is to derive a consistent picture of the carbon cycle by combining numerical models with the various streams of observational data that are becoming available. As the atmosphere integrates carbon dioxide exchange fluxes with the other components of the Earth system, atmospheric transport plays a central role. Our Carbon Cycle Data Assimilation activities are thus a natural extension of our work on atmospheric transport inversions. What we sketch below is joined work with our partners in the Carbon Cycle Data Assimilation System (CCDAS) (Consortium)
For a first pilot study we have coupled to the atmospheric transport model TM2 (Heimann, 1995) a model of the terrestrial biosphere (SDBM, Knorr and Heimann, 1995) that diagnoses carbon dioxide fluxes from vegetation index fields provided by remote sensing and modelled climatic forcing fields. Globally, twelve biomes (Collatz et al, 1998) are prescribed, and for each biome SDBM uses two tunable parameters, one for photosynthesis and one for heterotrophic respiration. In a first step (calibration step) we use observed atmospheric carbon dioxide concentrations to constrain these 24 parameters. A powerful gradient based optimisation procedure minimises the misfit between observed and modelled concentrations by iteratively varying the model parameters. The procedure uses the gradient (sensitivity) of the misfit function with respect to the parameters in order to determine new search directions in the parameter space. We estimate uncertainties in the optimal parameter set from uncertainties in both model and observations via the sensitivity of the concentration with respect to the parameters (Jacobian matrix) or the second derivative of the misfit with respect to the parameters (Hessian). In a second step (diagnostic step) we compute diagnostics such as mean carbon dioxide fluxes and their uncertainties from the optimal parameters and their uncertainties. We used the system to demonstrate the impact of a local (pseudo) flux measurement of prescribed accuracy on the uncertainties in parameters and diagnosed fluxes. For details see Kaminski et al. (2002). The derivative code used in this study was generated with TAF.
Next we have replaced SDBM by the much more sophisticated BETHY model
(Knorr, 1997,
2000),
in a version restricted to BETHY's photosynthesis, carbon and energy balance modules.
Hydrology and phenology are provided by an integration of the full BETHY version,
which has been calibrated against remotely sensed vegetation index data.
The coupled BETHY-TM2 model simulates the vegetation of thirteen plant
functional types (PFTs),
its carbon dioxide exchange fluxes with the atmosphere,
and the atmospheric carbon dioxide concentration.
In its current configuration, the model has 58 tunable parameters.
In contrast to SDBM, the model can run in prognostic mode,
i.e. it can predict the behaviour of the terrestrial biosphere,
e.g. under climate change. For details on the model see
Rayner et al. (2001) and
Scholze (2003).
We apply the same methodology as with SDBM (see also
Scholze (2003) and
Kaminski et al. (2003)).
In the calibration step, optimal parameter values plus uncertainties
are estimated from the combination of
observed atmospheric carbon dioxide, its uncertainties, and model
uncertainties.
The inversion procedure is based on first and second derivative
(gradient and Hessian) information.
The following figure shows the forward modelling chain:
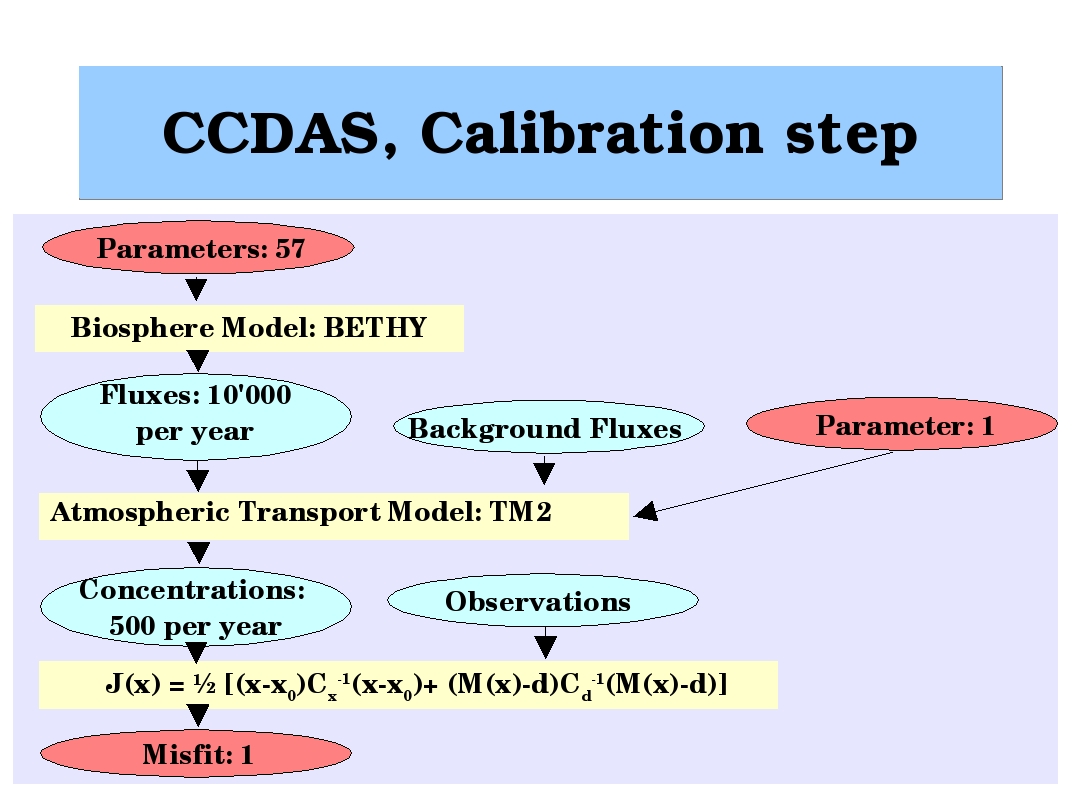
From parameters and their uncertainties we estimate uncertainties in
prognostic quantities such as mean carbon dioxide fluxes.
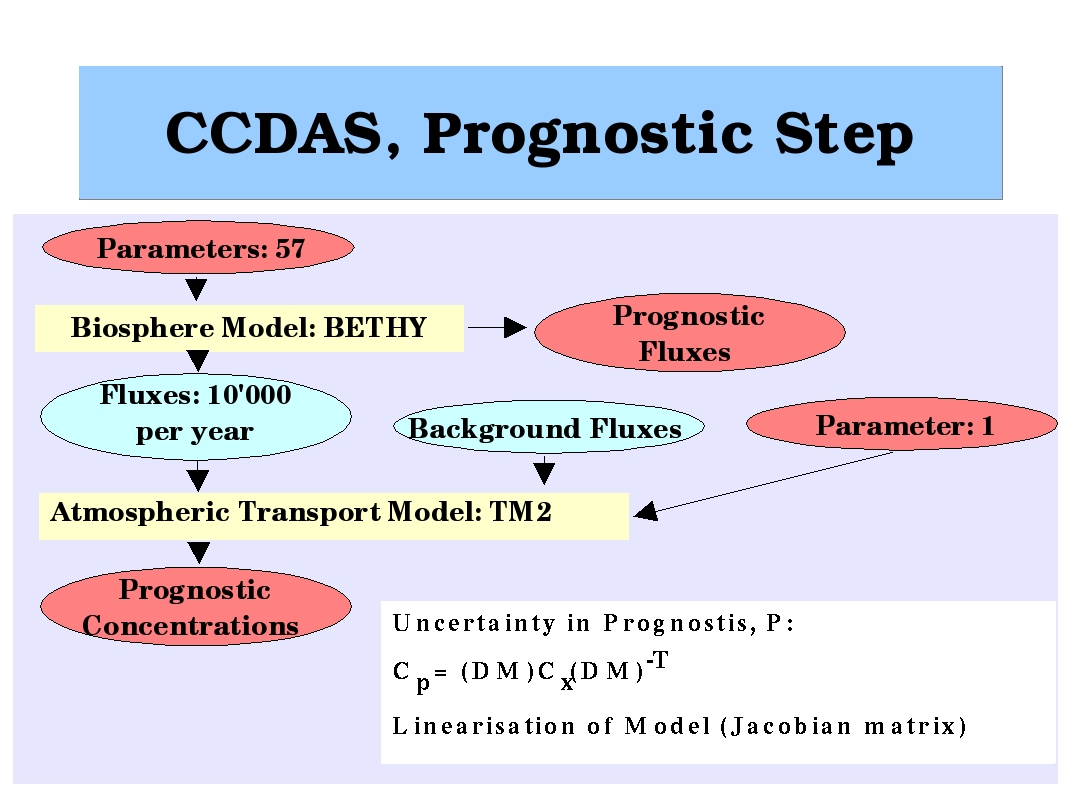
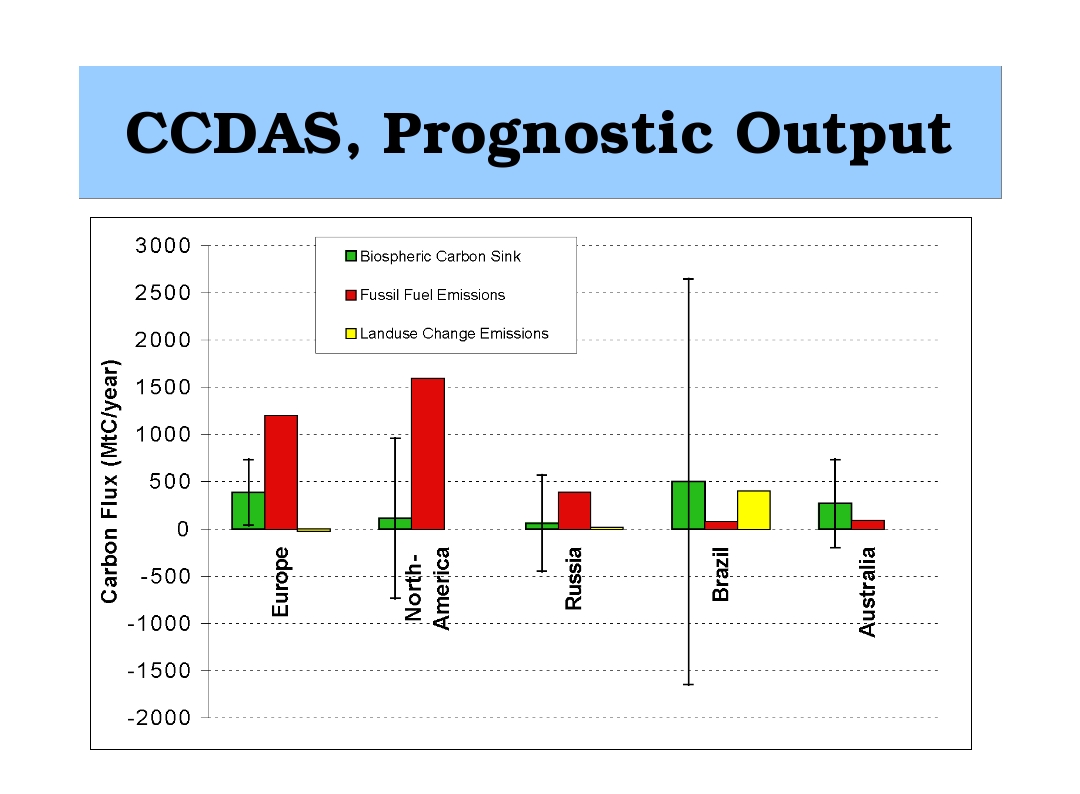
The following figures depict the modelling chain for the prognostic
step and an example of estimated mean fluxes and their uncertainties
taken from
Scholze et al. (2002):
For the initial version of BETHY the corresponding derivative codes
have been generated automatically by
TAF.
From this point on, BETHY has been developed further within CCDAS,
allowing immediate update of the derivative code by TAF.
This yields, at each development step,
both sensitivity information and systematic comparison with
observational data meaning that CCDAS is supporting model development.
The data assimilation activities, in turn, benefit from using the
current model version.
For details check the
complete list of references.